# redis数据持久化磁盘负载问题
redis虽为内存数据库,但为了做到服务down机重启后不丢失数据,从而能继续提供服务,需要让数据持久化到磁盘,所以在实际使用的过程中就容易遇到磁盘I/O负载问题。
# 问题描述
- 当请求量增长,key的操作频率增加,持久化操作变频繁后磁盘I/O 负载就会变高。
- 日志会出现"Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis."
- redis服务运行在aws的虚拟机上,磁盘类型为ebs的st1类型,此磁盘类型的底层物理架构为IOPS偏低的机械磁盘类型。
- 持久化同时开启rdb和aof.
# 监控截图
- openfalcon磁盘监控
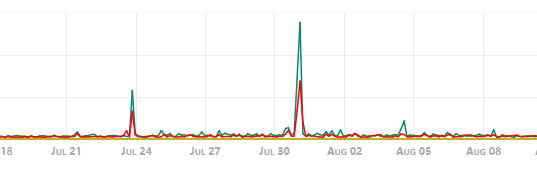
- atop磁盘监控

# redis持久化流程
- 客户端向服务端发送写请求(此时数据在客户端的内存中)
- 数据库服务接收到写请求的数据(此时数据存于服务端的内存中)
- 数据库服务调用系统API write操作,将数据往磁盘上写(此时数据在系统内存的内核缓冲区中)
- 操作系统将内核缓冲区的数据传到磁盘控制器中(此时数据在磁盘缓存中)
- 操作系统的磁盘控制器将数据写入实际物理介质中(此时数据真实落入磁盘)
# 问题分析
- 从监控可以看出,当负载增高的情况下,redis对磁盘的写请求增加,当超出磁盘的IOPS时,磁盘的响应会变慢导致阻塞,阻塞的出现会引起资源争抢的恶性循环,导致服务器负载飙升。
- redis是多路复用 (opens new window)的单进程服务。当AOF启用后,Redis处理完每个事件后会调用write将数据写入内核的buffer,如果write被阻塞,redis就无法处理下一个事件。
# 解决方法
- 将ebs的磁盘类型升级为gp2(底层物理架构为SSD类型),相对于st1类型的IOPS增大。(在实际实践中,虽然升级了此磁盘能缓解负载报警但不能根本解决磁盘性能问题,redis日志还是会出现"Asynchronous AOF fsync is taking too long.......")
- 修改vm.dirty_bytes值(系统的默认值为0):echo "vm.dirty_bytes=37748736" >> /etc/sysctl.conf && sysctl -p 【查看vm.dirty_bytes值:sysctl -a | grep vm.dirty_bytes】
- 最佳解决方案: 磁盘采用ssd固态硬盘的同时调整设置vm.dirty_bytes参数。因为高性能的磁盘类型能够很好地支撑redis同时做RBD和AOF持久化。